阅读预计 10 分钟
在过去一年里,随着大语言模型(Large Language Model, LLM)技术的飞速发展,越来越多的企业与开发者开始关注如何快速、高效地调用这些庞大的AI模型来满足业务需求。无论是对话机器人、文本生成、自然语言理解还是其他智能应用场景,“速度”与“稳定性”已经成为评估API服务质量的核心要素。然而,在当今琳琅满目的云服务市场中,究竟怎样才能选出一款兼具高效输出和灵活扩展的AI API?本文将以专业的“测评”视角,结合近期多项LM Speed速度测试(包括DeepSeek、Gemini、Qwen、GPT等众多主流模型),深入浅出地探讨其中的关键指标、技术挑战,以及我们在测试过程中的真实体验。文末,我们也会分享一个在速度与服务稳定性上都表现不俗的接口平台——中国AI API(ai.api.中国),以供对比与参考。
1. 为什么说“速度”就是“生产力”
在现实的AI应用中,速度(吞吐量与延迟)往往直接决定了用户体验与系统成本。举个例子,当你向一个大型语言模型发送一段指令,希望得到某段文案、翻译结果或代码辅助,如果响应速度极慢,就会大大降低用户满意度,更遑论在高并发场景下提供稳定服务。基于我们的多年观察,“速度”又可拆分为两方面:
吞吐量(Tokens per second, t/s):即模型每秒能够生成多少个Token(或字符片段)。吞吐量越高,意味着同等时间内能为更多用户完成任务或生成更长文本,适合大规模业务调用。
延迟(Latency):常见于“首字节延迟”“平均响应时间”等指标。例如模型开始生成第一批Token的时间(average first token latency),往往决定了用户最初的等待感受。而平均完成响应时间则影响整个对话的流畅度。
当我们的应用需要高并发、大批量文本处理时,若服务提供商的吞吐量不足,就会导致排队、超时甚至宕机;若延迟过高,则用户交互体验会大打折扣。因而,无论是初创企业还是成熟技术团队,评估AI API服务时,“速度”理应排在核心考量之列。
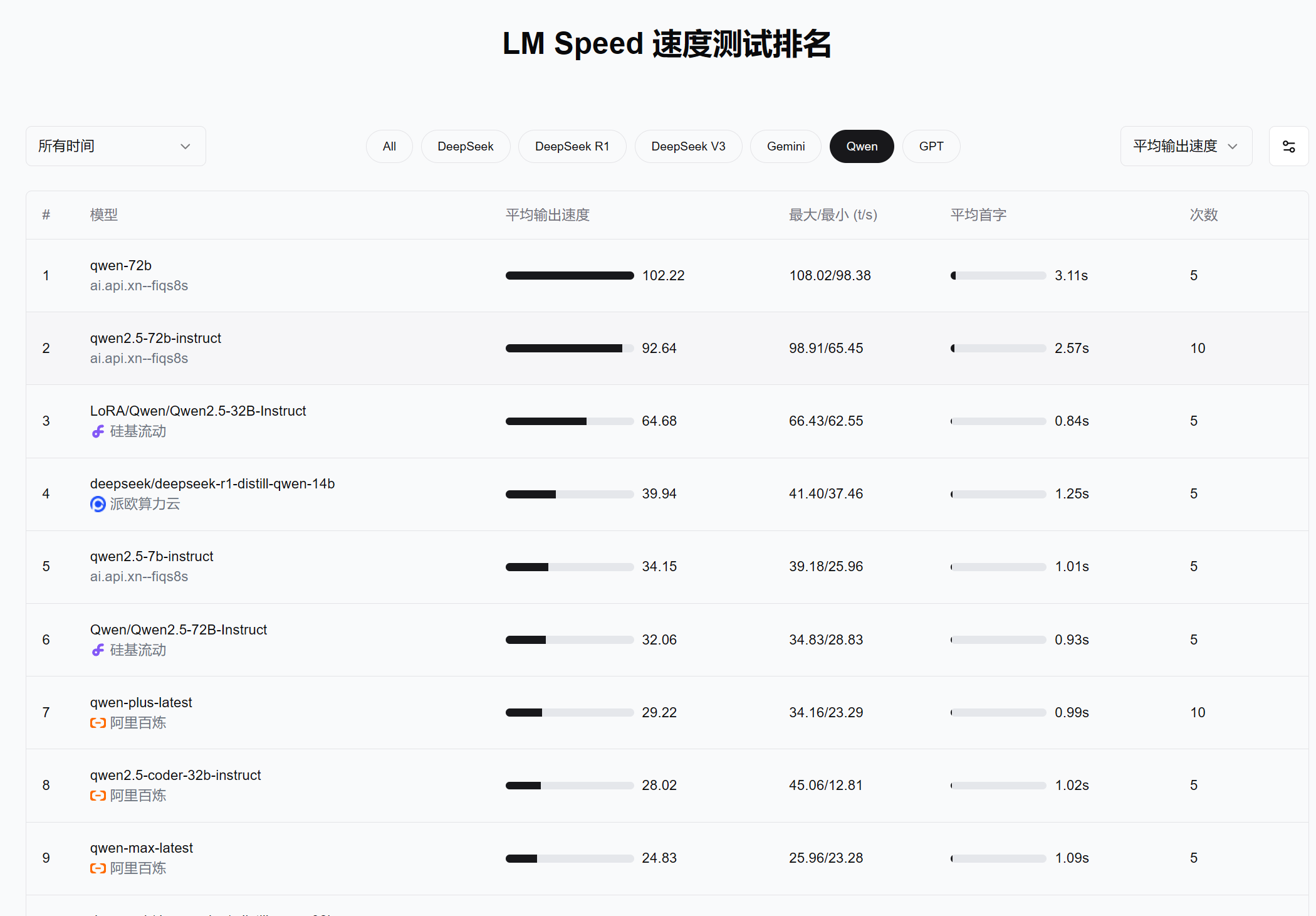
2. 测试指标:如何读懂LM Speed榜单
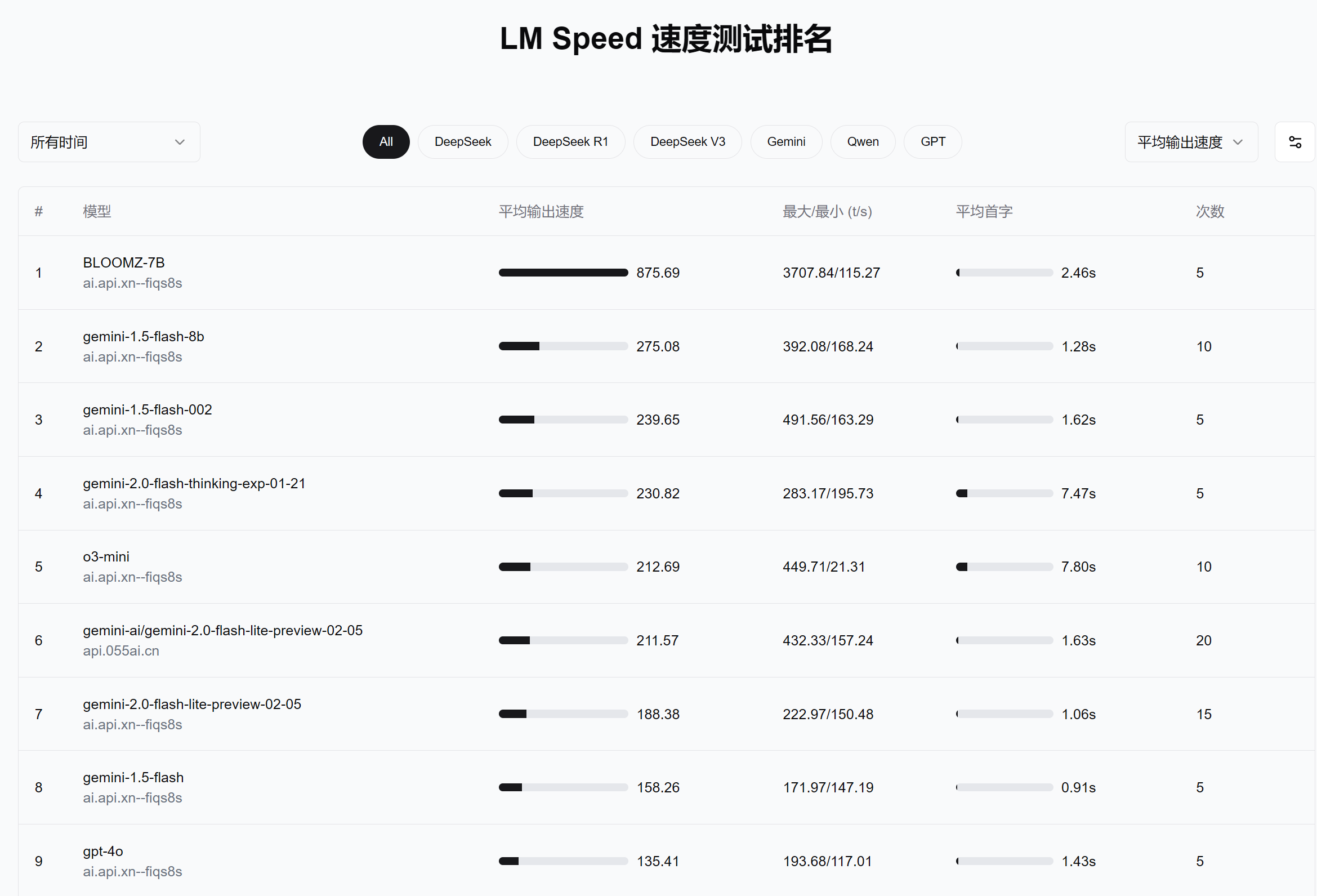
近期,我们获取了一系列关于多家AI模型服务提供商的测试数据。从图中可以看到,无论是DeepSeek R1/V3,还是Gemini、Qwen、GPT系列,都有相应的平均吞吐速度、最大/最小生成速度,以及平均首字时延等信息。下列是我们从中归纳的一些关键点:
平均输出速度(平均吞吐量)
例如,对于DeepSeek V3(67B)的不同部署节点,平均输出速度从10余t/s到二十多t/s不等,有的甚至能达到接近30 t/s。从这些数字可以推测,若一段文本含有300-400个Token,那么完成一则生成可能只需数秒。gemini-1.5-flash-8b能够达到275 t/s左右,甚至可在极端情况下飙升到392 t/s。这在小参数模型或部分优化版模型中并不罕见,但在实际业务场景能否维持高负载下的稳定性,则有待综合观察。
最大/最小值(t/s)
通过查看最大/最小生成速度的对比,可以判断在不同负载或并发量下模型可能出现的性能波动。举例来说,某些配置下的模型最高可达30+ t/s,但在最小值时却会降到仅5 t/s左右,这可能意味着服务端在资源调度、负载均衡、缓存机制等方面存在策略差异。
平均首字
这类指标(如“3.41s”“0.90s”等)通常代表了用户发起请求后,拿到第一批有意义Token的时间。如果应用场景要求“即时反馈”,首字延迟通常要越低越好;而对于批处理、离线任务,这一指标就不会太过敏感。
整体而言,我们看到类似“BLOOMZ-7B”在一份测试中爆出了惊人的875.69 t/s平均吞吐速度,这对需要海量文本处理的场景相当有吸引力。与此同时,也看到“gemini-2.0-flash-thinking-exp-01-21”这样更高参数、更复杂的版本在速度上略逊一筹,但可能在复杂语言理解、推理能力上更出色。至于DeepSeek与Qwen系列,也各有多版本测试数据,说明商用环境通常会提供多种配置选项,以满足不同用例的平衡点。
3. 影响速度的常见因素
大家在对比不同服务商的速度数据时,也许会产生疑问:为什么同样号称是70B左右的模型,速度可以相差好几倍?为什么某些8B、13B大小的模型,居然能“飙”到几百tokens/s?其背后涉及到多重因素:
硬件环境
GPU架构、数量、显存大小、NVLink带宽,甚至CPU与内存的配合度,都会影响模型加载与推理的并行效率。大型厂商往往拥有更顶尖的GPU集群,也会更熟练地做分布式部署和容器化优化,从而大幅提升推理速度。
模型结构与优化
一些开源模型本身体量接近,但内在的网络结构、注意力机制、激活函数等略有差异,就会在推理效率方面有明显区别。再加上有的团队使用了如TensorRT、ONNX Runtime、Sparse Quantization、Mixed Precision等技术对模型进行加速,也能带来显著的吞吐量提升。
API并发与负载均衡
同一模型在低并发下速度可能惊人,但一旦并发用户数大增,若负载均衡策略不够合理,速度就会骤降。部分厂商会在后台动态扩缩容,也可能针对不同客户等级分配不同优先级资源,导致实际体验出现差异。
网络状况与地域差异
测试者所在的网络环境、与服务端的物理距离、网络延迟,以及跨境路由因素,也都可能在T级别服务测试中被放大,从而造成性能落差。尤其对实时应用而言,任何数百毫秒的延迟累加都可能影响整体响应效率。
换言之,看到一份速度测试榜单时,我们既要欣赏“高速度”背后的技术投入,也要结合自身业务场景、预算成本和客户分布综合考量。比如对于重度依赖大文本生成的产品,我们需要关注那些平均吞吐量高、可支持高并发的节点;对于实时交互型应用,则需留意首字延迟和网络层优化。
4. 测试体验:如何对比不同平台
在此次对多家AI服务商进行的评测中,我们主要做了以下几件事,力图让测试过程更“公开、透明、可复现”:
多机位+多地域
测试团队成员在不同地域(包括国内和海外)通过相同脚本发起请求,记录下平均响应速度及吞吐量。这样可以避免仅在单一机房或单一地区测试所产生的偏差,也能更好地了解跨境调用时的稳定性。
统一调用逻辑
测试脚本在调用时,均采用相同的请求参数,如相似的对话或文本长度、固定的temperature或top_p等。若平台对超长输入有限制,则会提前说明或切分为若干段测试,避免因参数设置不同而影响结果对比。
观测多模型表现
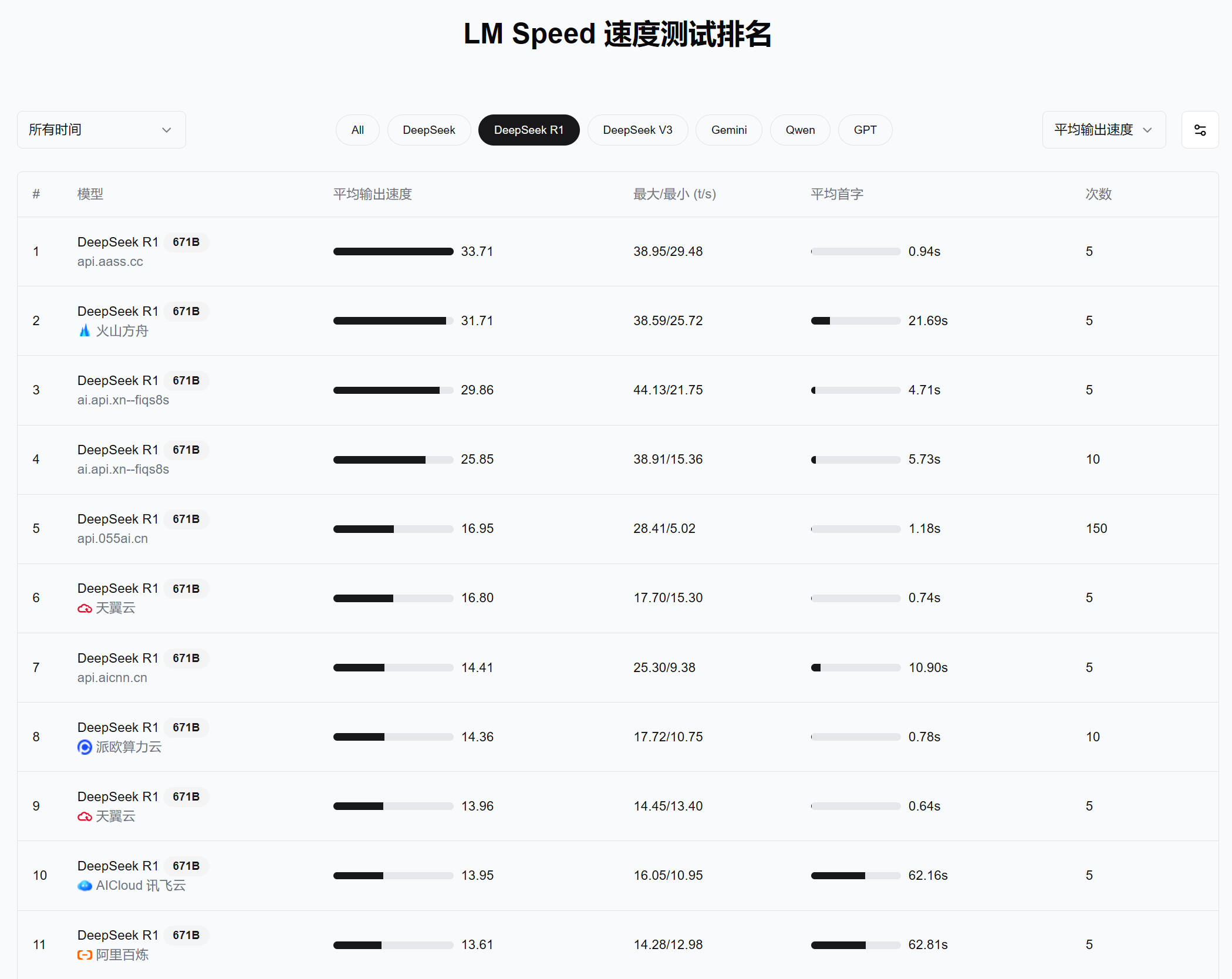
除了比较同一个模型在不同节点(不同厂商)的部署速度,我们也会对同一平台上不同模型的性能进行观察。比如同是DeepSeek R1系列的部署节点,就可以比对他们的吞吐量和稳定性差异;再例如Gemini 1.5与2.0系列在不同迭代版本下的速度变化。
通过这样的横纵对比,可以大致判断:某平台擅长部署大型模型,还是在小模型上更有优势?或者某模型在哪些特定优化版本上速度特别出色?
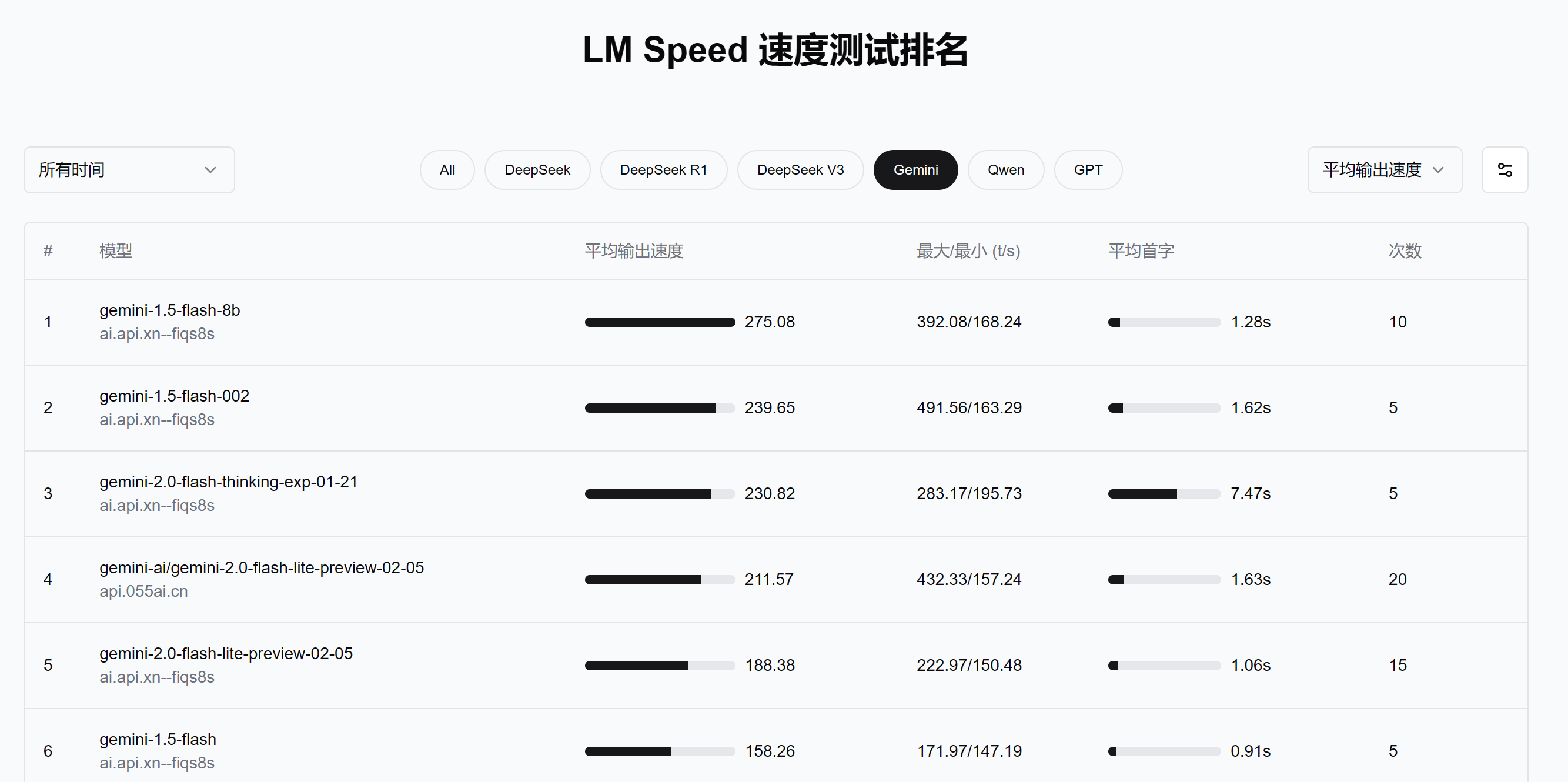
记录异常与重试
在高并发或长文本生成时,有时会出现超时、报错或无响应的情况。我们在正式测试中会做相应的重试机制,并记录异常率。如果在同样的负载条件下某平台异常率较高,那么即使它在正常情况下的速度再快,也难以进入实际生产环境。
最终,通过多角度、多模型测试,才能对各平台的综合实力与特性有更全面的感知,而不仅仅是“表格上那几个数字”那么简单。
5. 中国AI API(ai.api.中国) 的亮点与收获
在此轮测试里,我们也对中国AI API(ai.api.中国)进行深入观察。它所提供的服务同样支持多种模型,包括当前市面上热门的DeepSeek、Gemini、Qwen以及GPT系列,还接入了BLOOMZ、Code LLM等。以下是我们总结出的几个特点:
速度表现:稳定且提升空间大
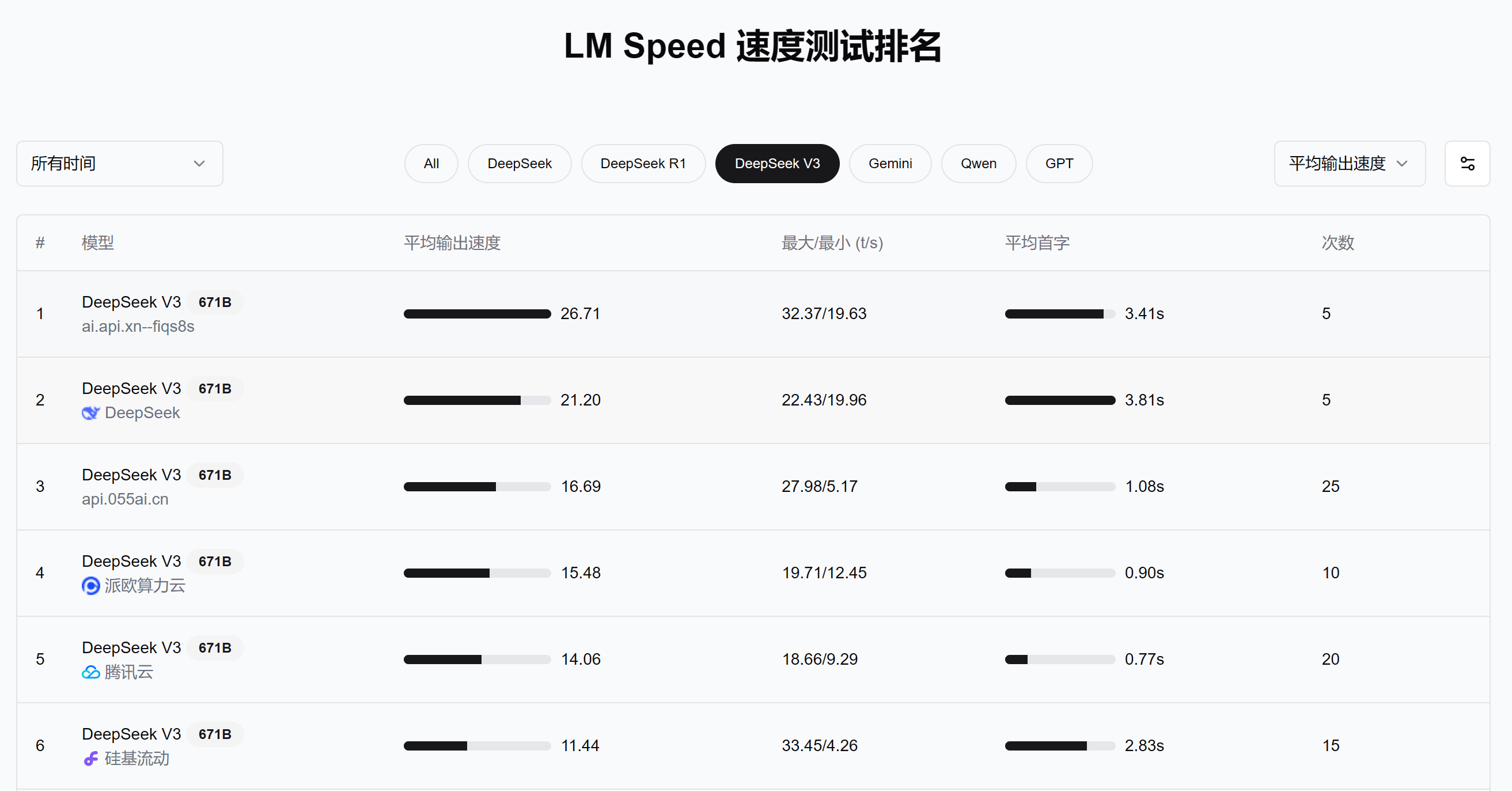
从对比表来看,部署在中国AI API上的部分DeepSeek R1/V3,有些节点的平均吞吐量保持在25~30 t/s之间,且最大值可冲到38 t/s上下,已能满足中大型文本生成需求。另外,一些轻量级模型(如8B、13B大小)的平均输出速度更是稳定在几十到上百t/s,在某些批量处理场景里非常可观。
按量付费与透明计费模式
许多开发者会担心调用大模型的费用过高或结算不透明。在中国AI API上,采用的是按Token或调用量计费的方式,且官网给出的策略清晰易懂,没有隐藏成本。可从小规模调用开始试用,再逐步扩容到更高配,十分灵活。
多种模型并行支持,兼顾广度与深度
大多数API服务商会在“主流模型”上发力,但当用户想要探索如Gemini某个“实验版”模型或Qwen的特定LoRA微调模型时,就不一定容易找到公共API。相比之下,中国AI API对接了目前市面上不少热门与前沿模型版本,甚至还有一些开源社区常用的小模型,涵盖内容创作、代码补全、多语言翻译等领域。
本土化与跨国服务并举
由于域名是“.中国”,这意味着在国内网络环境下访问更为顺畅,也更容易赢得本土合作伙伴与客户信任。同时,官方还提到他们在全球布点,准备做“遍地同台服务”,这对需要在海外落地或跨境布局的企业而言,也是一项可观的优势。
成熟的运维与技术支持
从测试体验来看,在调用量不断增加时,平台并未出现大范围错误或延迟激增的问题。官网亦提供了相对完善的API文档,常见功能示例齐全。遇到问题也能通过客服或工单渠道及时获得回复,对初创团队或中小企业来说,这种“一站式服务”能节省大量技术投入。
6. 写在最后:理性选择
从技术演进的角度而言,当前的AI大模型还处于高速迭代阶段。新版本、更大规模或更高精度的模型层出不穷,各厂商的底层优化与架构调整也在持续进行。因此,每次测评只能代表某个时间段、某些特定参数下的结果,无法定格在绝对意义上的“最终排名”。
但测评依然有其宝贵意义:它为开发者和企业提供了多维度的参考,让人们在决策时不至于“盲人摸象”。我们一方面可以通过数据对比来快速“过滤”那些明显无法达到生产级别的服务,另一方面也可以发现像中国AI API(ai.api.中国)这样,在速度、稳定性、价格与模型丰富度之间找到了平衡点的平台。
对于已经在使用大型语言模型的开发者,建议时不时跟进社区或行业报告,了解不同模型与API服务的最新表现;对于还在观望的团队,也可先在小规模场景下进行试点,测试其与自家业务的兼容度。毕竟,AI项目的成功不仅取决于模型本身,还包含了数据处理、产品设计、市场运营等多个环节的协同。
任何一次测评都非尽善尽美,也许在不久后又会有新的模型、新的部署优化方案出现,大幅刷新此前的性能记录。技术前沿日新月异,这正是AI行业的魅力所在。我们将持续跟进更多AI模型与API服务的最新动态,挖掘它们在实际应用中的优势与短板,希望每一位在AI时代乘风破浪的伙伴都能找到更适配的解决方案。
如果你对上文提到的速度指标、部署环境或模型特性还有兴趣,欢迎在评论区留言或直接访问中国AI API的官网进行进一步了解。无论你是科研工作者、企业管理者还是开发新人,这个快速发展的领域都蕴含着巨大潜力。让我们携手走进大模型新时代,让AI赋能更多场景,让技术造福更多人。让“速度”不仅是数字上的领先,也是真正可落地的生产力加速器。
相关推荐: 部署自己的云电脑,成本(真)五块钱,pv6+ddns
环境:ipv6网络,路由器软件版本1.09,DDNSgo 开源软件,光猫超管账户(用于关防火墙,咸鱼五块钱),RDP 材料:一台闲置电脑主机,路由器:TL-XDR3050易展版,一个域名 效果:随时随地外网连接,延迟极低,高峰期往返时长2ms,支持移动端,支持…
《 “最新API评测,谁还在盲人摸象” 》 有 3,301 条评论